
















Blog
More about Estuary and related technologies, straight from the team.
Our blog breaks down basic concepts and takes you into the minds of our engineers. We also dig into the business principles that guide our company and allow us to build great solutions for yours.

Jeffrey Richman · June 2, 2026
Migrating Postgres to DynamoDB (2 Easy Ways)

Jeffrey Richman · June 2, 2026
Jira to Redshift Integration (& How to Move Your Data Instantly)

Jeffrey Richman · March 5, 2026
Seamless SFTP/FTP to Snowflake Integration Guide
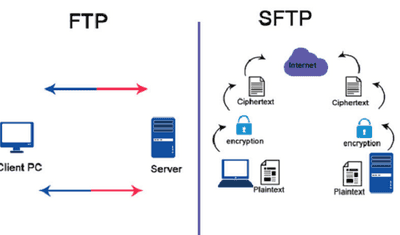
Jeffrey Richman · March 5, 2026
SFTP/FTP to BigQuery: How to Transfer Your Data in Minutes
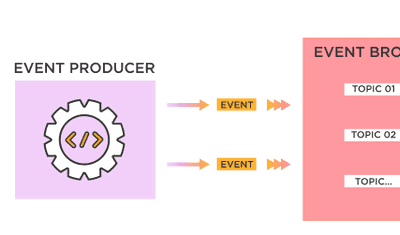
Jeffrey Richman · March 5, 2026
What Is Event-Driven Architecture? Comprehensive Guide 2026
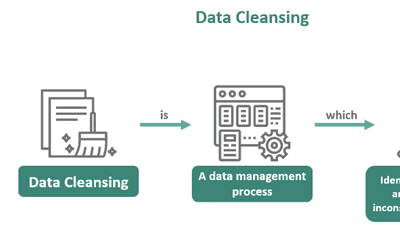
Jeffrey Richman · March 5, 2026
What Is Data Cleansing? (Tools, Process, & How-To)

Jeffrey Richman · March 5, 2026
7 Redis Data Types: Commands & Data Structures Guide 2024
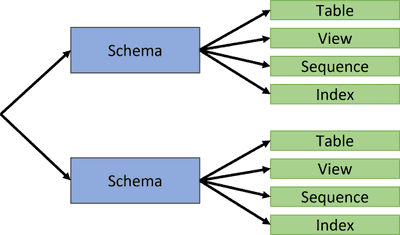
Jeffrey Richman · March 5, 2026
Postgres Schema Tutorial: How to Create Schema in PostgreSQL

Jeffrey Richman · March 6, 2026
Jira to BigQuery Integration: 2 Easy Methods (Step-by-Step Guide)

Jeffrey Richman · June 2, 2026
Connect Jira to PostgreSQL: The Ultimate Step-By-Step Guide

Jeffrey Richman · April 29, 2026
Amazon S3 to Snowflake: 2 Ways to Load and Sync Data

Jeffrey Richman · March 5, 2026
How to Load Data From JSON to BigQuery (3 Easy Methods)

Jeffrey Richman · March 5, 2026
9+ Proven Data Management Best Practices & Techniques 2026
Jeffrey Richman · March 19, 2026
Snowflake Connectors and Drivers: A Complete Guide to Seamless Data Integration

Jeffrey Richman · May 21, 2026
How to Connect Stripe to Snowflake: 3 Top Integration Methods

Jeffrey Richman · June 2, 2026
3 Easy Ways to Load Data From Stripe to Redshift
Jeffrey Richman · June 10, 2026
Data Integration vs ETL: Comprehensive Comparison Guide
Jeffrey Richman · February 19, 2026
Product Data Management: Understanding Its Role In Business
Jeffrey Richman · March 5, 2026
Data Integration in Data Mining: Get the Most Out of Your Data

Jeffrey Richman · February 9, 2026
Move Data from MariaDB to Snowflake: Step-by-Step Guide
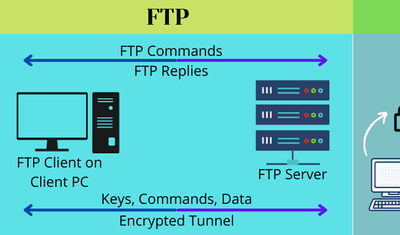
Jeffrey Richman · March 5, 2026
How to Connect SFTP/FTP to Redshift: 2 Easy Steps
Jeffrey Richman · March 5, 2026
Real-Time Data Replication: 5 Easy Strategies & Tools 2026
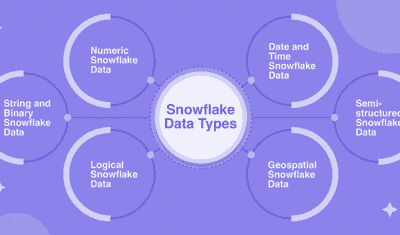
Jeffrey Richman · March 5, 2026
Snowflake Data Types: 6 Essential Types You Should Know
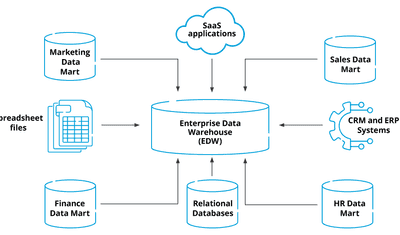
Jeffrey Richman · May 14, 2026
Enterprise Data Integration: Strategy, Challenges, and Best Practices

Jeffrey Richman · May 6, 2026
How to Import CSV into PostgreSQL: COPY Command, pgAdmin, and Automated Pipelines

Jeffrey Richman · March 5, 2026
Google Analytics 4 to Redshift Integration
Jeffrey Richman · June 2, 2026
MariaDB to Redshift: 2 Ways to Reliably Replicate Your Data
Jeffrey Richman · March 6, 2026
Connecting LinkedIn Ads to Redshift: 2 Easy Ways to Load Data

Jeffrey Richman · June 2, 2026
Connect BigQuery to Google Sheets: 2 Ways to Move Your Data

Jeffrey Richman · June 2, 2026
How to Connect Facebook Ads to Redshift (No Code, Real-Time)





























































