
















Blog
More about Estuary and related technologies, straight from the team.
Our blog breaks down basic concepts and takes you into the minds of our engineers. We also dig into the business principles that guide our company and allow us to build great solutions for yours.

Jeffrey Richman · March 5, 2026
Hevo vs Stitch: Things You Should Know

Jeffrey Richman · March 5, 2026
Connect Excel to PostgreSQL Database: A Quick and Easy Guide

Jeffrey Richman · March 5, 2026
Hevo Data vs. Fivetran: The Major Differences
Jeffrey Richman · March 5, 2026
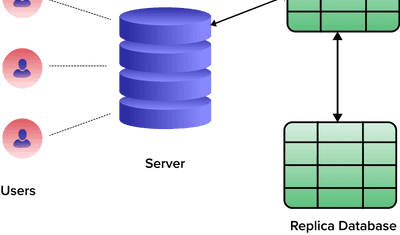
7 Data Replication Strategies & Real World Use Cases 2024
Jeffrey Richman · March 5, 2026
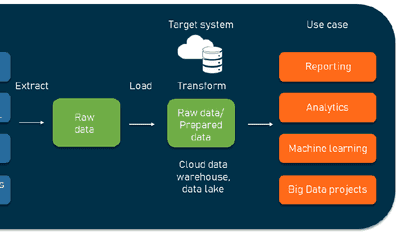
10 Best ELT Tools for a Modern Data Stack (2025)

Jeffrey Richman · March 5, 2026
Airbyte vs Stitch vs Estuary: 4 Important Differences

Jeffrey Richman · March 5, 2026
MongoDB to SQL Server Migration: 2 Easy Steps

Jeffrey Richman · March 5, 2026
Migrate MariaDB to SQL Server: 6 Easy Steps

Jeffrey Richman · November 12, 2025
How to Migrate PostgreSQL to SQL Server Step by Step

Jeffrey Richman · April 27, 2026
Postgres to MySQL Migration: 2 Easy Steps

Jeffrey Richman · March 5, 2026
How to Connect & Load Data from Instagram to BigQuery in Minutes

Jeffrey Richman · March 5, 2026
How to Move WooCommerce Data to Snowflake: Step-by-Step Guide

Jeffrey Richman · March 5, 2026
Comprehensive Guide for Connecting WooCommerce to BigQuery: Two Strategies Compared
Jeffrey Richman · March 5, 2026
10 Event-Driven Architecture Examples: Real-World Use Cases

Jeffrey Richman · March 5, 2026
Criteo to Snowflake: 2 Easy Ways to Move Your Data

Jeffrey Richman · March 5, 2026
Mixpanel to Redshift: The Ultimate Guide for Easy Integration

Jeffrey Richman · March 6, 2026
Connect Mixpanel to BigQuery: Real-Time Integration Guide

Jeffrey Richman · March 5, 2026
How to Migrate a MySQL Database Between Two Servers

Jeffrey Richman · March 5, 2026
MySQL to SQL Server Migration: Step-by-Step Guide (2025)

Jeffrey Richman · March 6, 2026
How to Load Data from NetSuite to BigQuery - 2 Easy Methods

Jeffrey Richman · March 5, 2026
Guide For Connecting NetSuite to Redshift: Manual vs. SaaS Data Transfer

Jeffrey Richman · March 5, 2026
How to Move Data From Braze to Snowflake (4 Easy Ways)

Jeffrey Richman · March 5, 2026
DynamoDB to Snowflake Data Integration in Minutes (3 Easy Ways)

Jeffrey Richman · March 5, 2026
How to Connect Pinterest Ads to BigQuery: 2 Easy Steps

Jeffrey Richman · February 9, 2026
How to Integrate Google Analytics 4 to Snowflake: 3 Methods

Jeffrey Richman · March 6, 2026
DynamoDB to BigQuery ETL: Move Data in Just 2 Easy Steps

Jeffrey Richman · December 15, 2025
DynamoDB to Redshift: 3 Efficient Ways to Move Data

Jeffrey Richman · March 6, 2026
DynamoDB to Postgres Migration: A Step-By-Step Guide

Jeffrey Richman · March 5, 2026
Migrating Postgres to DynamoDB (2 Easy Ways)

Jeffrey Richman · March 5, 2026
Jira to Redshift Integration (& How to Move Your Data Instantly)




























































