
















Blog
More about Estuary and related technologies, straight from the team.
Our blog breaks down basic concepts and takes you into the minds of our engineers. We also dig into the business principles that guide our company and allow us to build great solutions for yours.

Jeffrey Richman · June 2, 2026
Data Pipeline Architecture: Patterns, Best Practices & Key Design Considerations
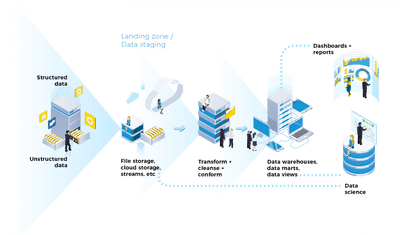
Jeffrey Richman · June 2, 2026
How to Build Real-Time Data Pipelines: A Comprehensive Guide
Phil Fried · June 2, 2026
Why TypeScript for real-time data transformation?
Jeffrey Richman · June 2, 2026
Streaming Data Pipelines: Must-Have Features & Complexities
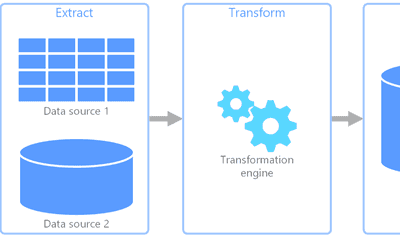
Jeffrey Richman · July 7, 2026
What Is an ETL Pipeline? How It Works, Tools & Examples
Jeffrey Richman · May 26, 2026
Data Pipelines Explained: What They Are and How They Work in 2026

Olivia Iannone · June 2, 2026
The problem with credit-based pricing for data platforms
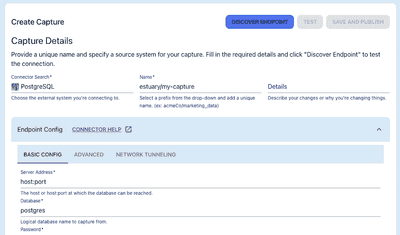
Olivia Iannone · June 2, 2026
How to create a real-time materialized view in PostgreSQL
Olivia Iannone · May 11, 2026
Everything you actually need to know to use Estuary

Olivia Iannone · June 2, 2026
Four software engineering best practices to improve your data pipelines

Olivia Iannone · June 2, 2026
How to prevent your data warehouse from becoming a data swamp

Olivia Iannone · June 2, 2026
Why ELT won’t Fix Your Data Problems

David Yaffe · June 2, 2026
Announcing Estuary's partnership with Rockset

Olivia Iannone · March 5, 2026
DataOps for business: A comprehensive introduction

Olivia Iannone · March 3, 2025
Why you don’t actually need a reverse ETL platform
Olivia Iannone · June 2, 2026
Data for all: Why data democratization matters at every scale

Olivia Iannone · June 2, 2026
Understanding the modern data stack, and why open-source matters

Olivia Iannone · July 20, 2026
MySQL Change Data Capture (CDC): Complete Guide

Jeffrey Richman · June 2, 2026
Complete Guide to PostgreSQL Change Data Capture (CDC): Best Methods

Olivia Iannone · April 29, 2026
3 reasons to rethink your approach to change data capture

Jeffrey Richman · May 1, 2026
What is Change Data Capture (CDC)? Benefits and Use Cases

Olivia Iannone · June 2, 2026
How new pipeline tools are changing data engineering in the 2020s

Olivia Iannone · June 2, 2026
Try it yourself: Continuous materialized views in PostgreSQL

Olivia Iannone · June 2, 2026
This article won’t tell you how to build a data mesh
Olivia Iannone · June 2, 2026
The power and implications of data materialization

Olivia Iannone · June 2, 2026
Connector stories: Snowflake and BigQuery

David Yaffe, Johnny Graettinger · June 2, 2026
The Estuary story and guiding principles

Olivia Iannone · June 2, 2026
Database vs data warehouse vs data lake: Key differences and usage
Olivia Iannone · June 2, 2026
Three data scaling pitfalls and how to avoid them
Olivia Iannone · June 2, 2026
Connector stories: Apache Kakfa




























































