
















Blog
More about Estuary and related technologies, straight from the team.
Our blog breaks down basic concepts and takes you into the minds of our engineers. We also dig into the business principles that guide our company and allow us to build great solutions for yours.

Jeffrey Richman · February 28, 2025
PostgreSQL Data Types Explained With Examples
Olivia Iannone · June 2, 2026
What is SQL Server CDC (Change Data Capture): The Guide
Jeffrey Richman · June 8, 2026
Real-Time Data Streaming Architecture: Benefits, Challenges, and Impact
Jeffrey Richman · June 2, 2026
What is Real-Time Data Streaming: Architecture, Tools & Use Cases

Jeffrey Richman · June 25, 2026
3 Ways to Stream Data from Postgres to Elasticsearch
Jeffrey Richman · March 5, 2026
Firestore vs. Realtime Database: Which Performs Better?
Olivia Iannone · June 2, 2026
How to Analyze Google Firestore Data: 4 Options By Use Case

Jeffrey Richman · July 17, 2026
Real-Time Data Warehouse: Architecture, Benefits, and How to Build One
Jeffrey Richman · June 2, 2026
How To Replicate Data From MySQL To Parquet: Full Guide

Mahdi Dibaiee · June 2, 2026
Capturing data from Salesforce: Historical and Real-Time
Jeffrey Richman · September 25, 2025
Data Pipeline Examples and Use Cases: A Complete Guide for 2025

Jeffrey Richman · July 6, 2026
What Is Real-Time Data Processing? How It Works, Examples, and Tools

David Yaffe · June 2, 2026
The Real-time Data Landscape

Jeffrey Richman · May 19, 2026
PostgreSQL to BigQuery: 2 Best Ways to Sync Data Fast

Jeffrey Richman · June 10, 2026
12 Best Data Pipeline Tools in 2026: Compared by Use Case

Jeffrey Richman · July 17, 2026
Real-Time Data Explained: Types, Benefits, and Use Cases
Jeffrey Richman · June 2, 2026
What Are Data Connectors? Importance, Types, And Examples

Jeffrey Richman · June 2, 2026
How To Connect Google Sheets To PostgreSQL: 2 Easy Steps

Olivia Iannone · June 2, 2026
How to sync Firestore data to Snowflake for data analytics
Jeffrey Richman · June 2, 2026
Confluent Kafka vs Apache Kafka vs Estuary: 2025 Comparison

Jeffrey Richman · June 2, 2026
How to Move Data from MySQL to Snowflake: Step-by-Step Guide

Jeffrey Richman · June 2, 2026
How To Connect MySQL To BigQuery: 2 Straightforward Ways

Jeffrey Richman · June 25, 2026
How to Sync MySQL to Elasticsearch in Real-Time (No Code + Logstash Options)

Jeffrey Richman · June 2, 2026
How to Connect MySQL to Google Sheets: 3 No-Code Methods

Jeffrey Richman · June 27, 2026
How to Migrate MySQL to PostgreSQL: A Step-by-Step Guide (2026)
Jeffrey Richman · March 5, 2026
What Is An Automated Data Pipeline — Examples & Use Cases

Jeffrey Richman · April 1, 2026
Top 7 Airbyte Alternatives & Competitors in 2026 (Compared)

Olivia Iannone · June 2, 2026
Graphing GitHub CI build times with remote transformations and Estuary

Jeffrey Richman · June 2, 2026
Meltano vs Airbyte — A Decision Guide
Olivia Iannone · June 2, 2026
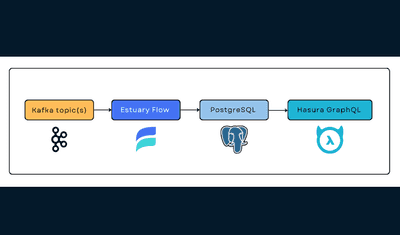
Real-Time Kafka to GraphQL: A Step-by-Step Tutorial




























































