













One platform for all data movement
Unify CDC, batch, streaming, and app syncs with a single managed platform purpose-built for real-time ETL and ELT. Start streaming for AI and ops or batch-load for analytics — all set up in minutes with millisecond latency.
- No credit card required
- 30-day free trial





Right-time data movement
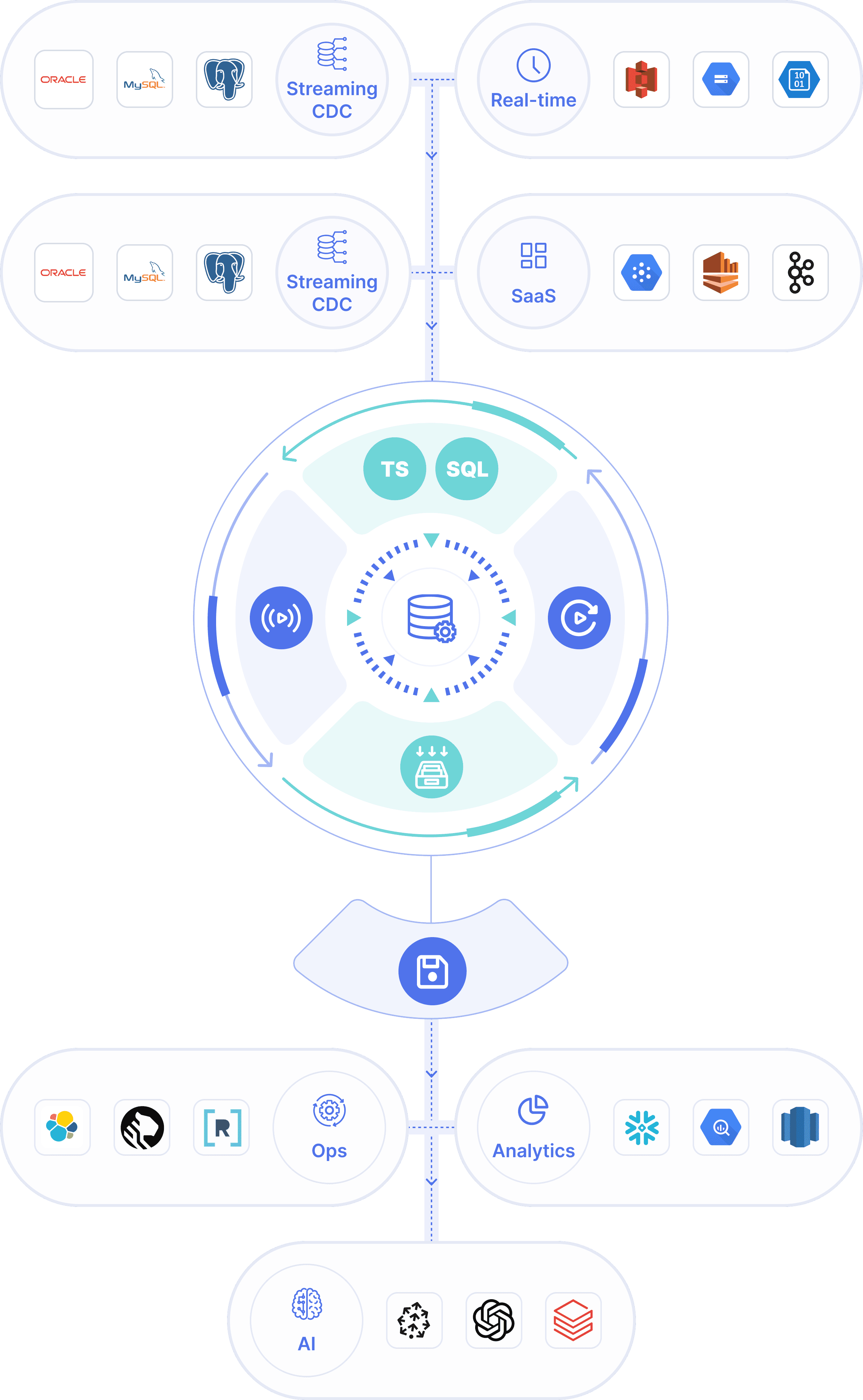
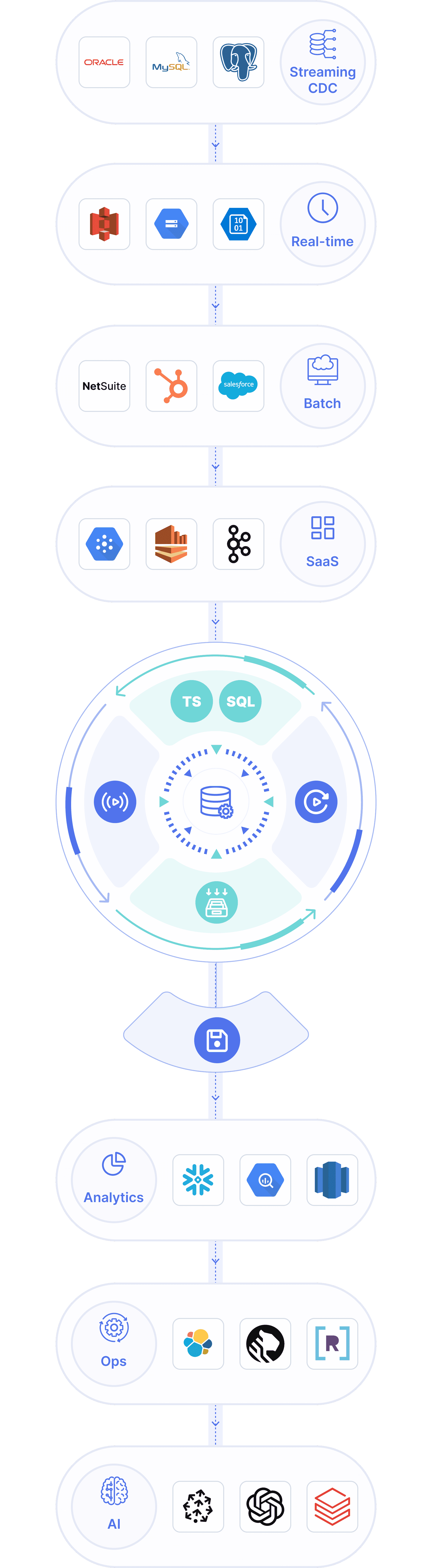
Estuary
![Capture]()
![Capture]()
![Capture]()
Capture
![Stream, Store, Transform, Replay]()
![Stream, Store, Transform, Replay]()
![Stream, Store, Transform, Replay]()
Stream, Store, Transform, Replay
![Materialize]()
![Materialize]()
Materialize






















































Key features
Estuary stands out because it brings together the best of CDC, real-time, and batch with modern data engineering best practices, enabling the best of both worlds, without managing infrastructure.
No-code connectors
Connect apps, analytics, and AI using 200+ of streaming CDC, real-time, and batch no-code connectors built by Estuary for speed and scale.
End-to-end CDC
Perform end-to-end streaming CDC.
- Stream transaction logs + incremental backfill.
- Capture change data to a collection.
- Reuse for transformations or destinations.
Kafka compatibility
Use Estuary Dekaf to connect any Kafka-compatible destination to Estuary as if it were a Kafka cluster via the destination's existing Kafka consumer API support.
Real-time and batch
Stream data from each source, then load each destination at any speed, from <100ms for operations or hour+ intervals, for analytics.
Private storage
As you capture data, Estuary automatically stores each stream as a reusable collection, like a Kafka topic but with unlimited storage. It is a durable append-only transaction log stored in your own private account so you can set security rules and encryption.


ELT and ETL
Transform and derive data in real-time (ETL), using SQL or Typescript for operations, or use dbt to transform data (ELT) for analytics.
Many to many
Move data from many sources to collections, then to many destinations all at once. Share and reuse data across projects, or replace sources and destinations without impacting others.
Backfill and replay
Reuse collections to backfill destinations enabling fast and effective one-to-many distribution, streaming transformations and time travel, at any time.
Schema evolution
Automatically inferred and managed from source to destination using schema evolution.
- Automated downstream updates.
- Continuous data validation and testing.
CLI and API Automation using flowctl.
Multi-cloud deployment
Deploy each capture, SQL or TypeScript task, and materialization of a single pipeline in the same or different public or private clouds and regions.
Create dependable, right-time data pipelines in minutes
Connect hundreds of sources and destinations with no-code pipelines that give you full control over latency, cost, and deployment — all from one platform.


1. Integrate Sources
Add sources and destinations using agentless, no-code connectors for CDC, batch, and streaming across databases, SaaS, and data warehouses.
See connectors

2. Manage Cadence
Choose the right cadence for every connection from sub-second streaming to scheduled batches and optimize speed or cost based on your workload.

3. Ensure Reliability
Choose between maintaining a mirrored copy of your data or a full audit log with exactly-once delivery, guaranteed.







Configure or code to power AI with right-time data
Build dependable, AI-ready data pipelines using the right mix of no-code configuration and developer tools. Estuary unifies batch and streaming so enterprises can move, transform, and sync data continuously across their stack - fueling analytics, operations, and AI.
Use 200+ of no-code connectors for apps, databases, data warehouses, and more.
Build visually in the Estuary UI or develop with the flowctl CLI.
Transform using Streaming SQL (ETL) and TypeScript (ETL) or dbt (ELT) in your warehouse — delivering fresh, right-time data to power AI models and applications.


Use modern DataOps
Rely on built-in data pipeline best practices, integrate tooling, and automate DataOps to improve productivity and reduce downtime.
Automate DataOps and integrate with other tooling using the flowctl CLI.
Use built-in pipeline testing to validate data and pipeline flows automatically.
Select advanced schema detection and automate schema evolution.




Increase productivity.
Reduce costs.
Focus on building, not babysitting pipelines. Estuary helps teams move faster and spend less with dependable, right-time data movement and predictable pricing.
Build and scale pipelines 4x faster with fewer failures and less manual troubleshooting.
Cut data costs by 40-60% with transparent, throughput-based pricing (see pricing.)
Minimize source strain by capturing data once, then sync it everywhere you need.
Optimize destination spend with right-time updates—stream in real time when it matters, batch when it doesn't.


Deliver right-time data at scale
Estuary powers dependable data movement at massive scale - unifying batch, streaming, and CDC pipelines in production for thousands of enterprises. Built for the world's most demanding workloads, Estuary moves data over 7+ GB/sec with sub-100 ms latency.
Stream or batch data at any scale from sub-second to scheduled updates.
Ensure data integrity with exactly-once delivery and deterministic recovery.
Monitor performance with built-in alerting, load balancing, and failover designed for enterprise reliability.



7+GB/sec
Single dataflow
5500+
Active users
<100ms
Latency
Enterprise-grade security & reliability
Your data stays in your environment, Estuary simply moves it securely between systems. With enterprise-grade compliance and private deployment options, you can meet the strictest governance requirements without sacrificing performance.
We never store your data - we just help move it
HIPAA, GDPR, CCPA, and CPRA compliant
SOC 2 Type II certified


Streaming ETL vs. Batch ELT


Streaming ETL
With Estuary, you extract data exactly and only once using CDC, real-time, or batch; use ELT and ETL; and deliver to many destinations with one pipeline.

How Estuary compares
Feature Comparison
| Estuary | Batch ELT/ETL | DIY Python | Kafka | |
|---|---|---|---|---|
| Price | $ | $$-$$$$ | $-$$$$ | $-$$$$ |
| Speed | <100ms | 5min+ | Varies | <100ms |
| Ease | Analysts can manage | Analysts can manage | Data Engineer | Senior Data Engineer |
| Scale | ||||
| Maintenance Effort | Low | Medium | High | High |




Ready to start?
Build a pipeline
Try out Estuary free, and build a new pipeline in minutes.
Set up an appointment
Set up an appointment to get a personalized overview.

