





















Data Mesh architecture has gained significant attention in recent years as a novel approach to managing data within organizations. With the ever-increasing complexity of data, monolithic data architectures are struggling to meet the evolving needs of businesses. Data Mesh architecture has emerged as a promising solution that offers a decentralized and domain-oriented approach to managing data.
This new approach is not without its challenges. Organizations need to understand and adapt to the complexities of decentralized data management. They should also establish best practices to make the most of this innovative architecture.
In this article, we will look into the functions, best practices, and principles of Data Mesh architecture to empower you with practical insights and knowledge. By the time you’re done reading this 7-minute guide, you'll have a solid understanding of how this Data Mesh paradigm can transform the way data is handled within your organization.
What Is A Data Mesh?

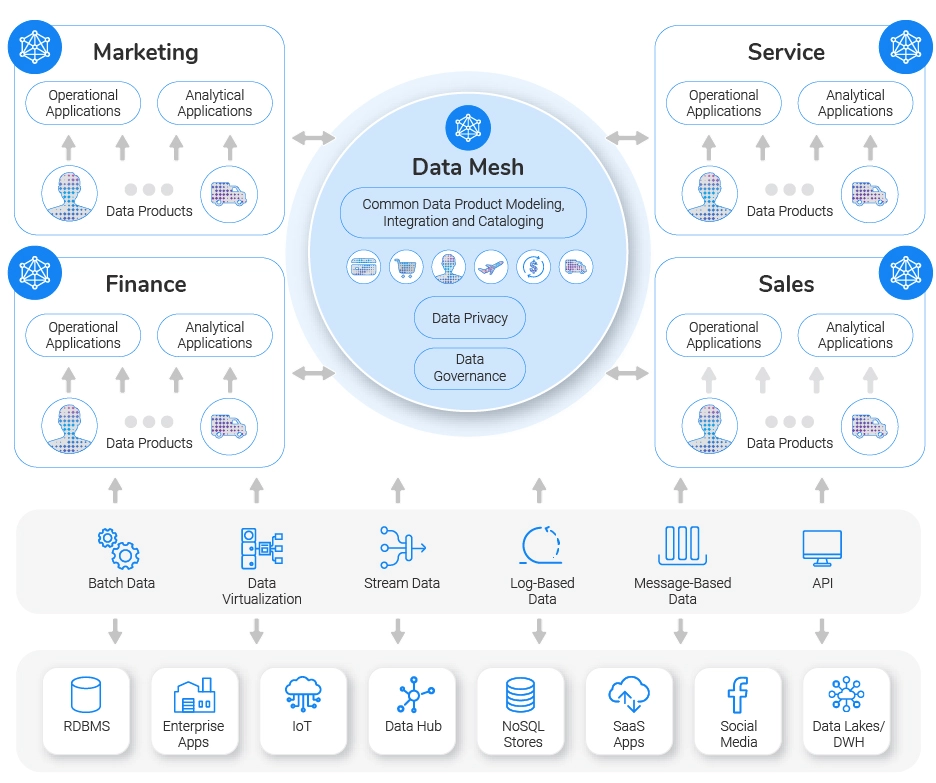
Data Mesh is all about placing power in the hands of the people who use the data. Traditionally, data was controlled by a central authority but in a Data Mesh, ownership is shared among various data teams. Each team becomes a steward of its own data to ensure its accessibility, accuracy, and meaningfulness.
The best thing about Data Mesh is the balance it strikes. While offering autonomy, it also ensures consistency across the organization which enhances the overall experience of data usage.
Here's how it works:
- Autonomy: Each team develops, deploys, and operates its own data services, cutting down on red tape and delays.
- Self-service: Teams have a self-serve data platform to manage their data. They're in control, defining their data needs.
- Decentralization: Rather than one team hoarding all the data, Data Mesh breaks down these data silos and shares the data across different teams.
4 Core Principles Of Data Mesh Architecture


The Data Mesh approach is based on 4 core principles that ensure scalability, agility, quality, and integrity of your data across the organization.
Domain-Oriented Data Ownership
Domain-oriented data ownership is a foundational pillar of Data Mesh architecture. Domain teams are imbued with the authority to manage their respective data assets. This aligns with the principles of domain-driven design, facilitating a shift of data ownership from a centralized unit to individual domain teams.
- Team Boundaries: Each domain operates as an independent data entity. The delineation of team boundaries aligns directly with their specific system's bounded context.
- Ownership: These teams don’t merely function within their data sphere - they assertively manage them. They undertake the responsibility of developing, deploying, and overseeing their own data services.
- Customization: This dispersion of authority enables each team to tailor their data models to their unique needs.
Data As A Product
Within the framework of Data Mesh, there's an innovative principle called 'Data As a Product'. This perspective urges us to view data not just as an output but as a valuable commodity.
- Public API mindset: It's helpful to consider domain data like a public API. It's there to be accessed, used, and even scrutinized by others.
- Domain responsibility: Each domain team isn't just holding onto its data; it's looking after a product. That product needs to meet the needs of other domains which become its consumers.
- Consumer support: Domain teams have to cater to the needs of their 'customers' - other domains in the organization. This entails offering secure, up-to-date data that's ready to be used.
Self-Service Data Infrastructure
Imagine Self-service data infrastructure as a digital toolkit offered by a specialized infrastructure team in your organization. It furnishes necessary tools, systems, and functionalities.
- Specialized team: A dedicated data platform architecture team provides the infrastructure, acting as a behind-the-scenes tech crew.
- Interoperability: This model ensures that data products can be used across all domains, fostering a collaborative and efficient data environment.
- Platform thinking: By applying platform thinking to data infrastructure, we establish a system that lets every data domain team become both data consumers and providers of data products.
Federated Computational Governance
Federated computational governance is a guiding principle of Data Mesh and acts as a fine balance between centralized control and distributed authority.
- Compliance: The primary goal of federated governance is to cultivate a compliant data ecosystem.
- Balanced authority: Each domain has the autonomy to make decisions and handle its data, all while adhering to the organization's rules and governmental regulations.
- Standardization: A unified governance group promotes standardization across the Data Mesh. This ensures that all data products can work together smoothly, achieving interoperability.
Understanding The Dynamics Of Data Mesh Architecture


Data Mesh architecture is a decentralized approach that helps each domain team manage its own operational and analytical data. The teams are responsible for ingesting operational data, creating analytical data models, and conducting their analysis.
However, this isn't a free-for-all situation. While each domain operates independently, there's a clear set of global policies they agree on, like interoperability, security, and documentation standards. This is facilitated by a federated governance group, ensuring each domain knows how to discover, understand, and utilize available data products effectively.
The data platform team plays a critical role here. They provide a domain-agnostic data platform that eases the creation of data products and analysis for domain teams. There's also an enabling team dedicated to guiding domain teams on data modeling and maintenance of interoperable data products.
Knowing the intricacies of Data Mesh architecture, it’s also important to explore the major functions that underpin its effectiveness.
7 Major Functions Of Data Mesh Architecture
Here are the 7 core functions of the Data Mesh architecture.
Data Product & Data Contract
A data product stands as a self-sufficient unit, integrating all the required data, code, and interfaces. It functions like an analytical microservice for satisfying the data requirements of its own domain team and potentially others.
Key responsibilities of a data product include establishing connections with various sources like operational systems or other data products, and executing data transformations. Data products distribute data sets across one or more output ports, such as:
- Tables in Google's BigQuery
- Interactive dashboards in Looker
- Parquet files stored in Amazon's S3
- Detailed reports in PDF format sent via email
- Machine learning models represented as ONNX files
- Delta files located in Azure Data Lake Storage Gen2
Whereas a data contract is a formal agreement that outlines the terms of use for a data product. It includes details about the data provider and consumer, the purpose of data, schema, semantics of data, and cost details.
These contracts come into effect when a consumer requests data access and the provider approves it. Either party can cancel a data contract with a defined notice period.
Data contracts create stability, trust, and quality within the Data Mesh and even facilitate automation. For instance, when a data contract is concluded, permissions for the output port can be automatically set up on the data platform. The permissions are also automatically deleted when the contract is terminated.
Federated Governance
The federated governance model plays a crucial role in managing a Data Mesh architecture, offering a blend of functionalities that streamline data operations.
- Uniform Data Access: A key functionality lies in defining a uniform and secure method for accessing data products.
- Privacy and Compliance Policies: The federated governance group also sets global policies to protect sensitive information and uphold industry compliance.
- Interoperability policies: A core functionality of federated governance is establishing guidelines for data interoperability to ensure consistency in how data products are utilized.
- Data discovery and documentation: Federated governance mandates systematic documentation of data products to facilitate easy discovery and understanding. This transparency ensures that all teams know about data availability and structure.
Data Transformations


Data transformation primarily begins with preprocessing where raw and unstructured operational data undergo significant changes. This data, which may originate from various data sources, is initially cleaned and structured into 2 essential components:
- Events are small, immutable, and highly domain-oriented. They represent specific actions or occurrences like 'order purchased' or 'shipment delivered’.
- Entities, on the other hand, are business objects, such as shipments or articles. The state of these entities is typically captured as a series of snapshots or history with the latest snapshot signifying the current state.
Data from other teams integrate as external data. When these data products from other teams are well-governed, the integration process can be smooth and lightweight. However, when dealing with data imports from legacy systems, an external area often acts as an anti-corruption layer, safeguarding the Data Mesh system.
Finally, aggregations bring data together to answer analytical questions. Domain data can be published to other teams by defining a data contract.
Data Ingestion
Following transformation, the ingestion process steps in to bring the structured data into the data platform.
In conjunction with domain events, real-time data ingestion swiftly integrates business indicators into the data platform, enriching the analytics process with well-defined and immutable data.
An essential part of data ingestion involves tracking and recording changes in entities. Techniques like Aspects or EntityListeners enable the creation of events each time an entity changes. These events then flow into the data platform, enhancing the analytic capabilities.
When adjustments to operational software are unfeasible, Change Data Capture (CDC) offers a solution by providing direct tracking and streaming of database changes.
Additionally, scheduled ELT or ETL jobs assist in data ingestion from legacy systems that cannot support real-time data capture. Data preprocessing refines the data which involves deduplication, PII data anonymization, and ingestion of internal analytical events.
The process concludes with the effective management of changes in the state of entities and aggregates in databases, providing a complete view of data evolution for nuanced analytics.
Data Cleaning
Data cleaning begins with structuring. It involves transforming data from unstructured or semi-structured formats, like JSON fields, into a database format that is easier to comprehend.
The next steps are mitigating structural changes and deduplication. This involves replacing empty values with appropriate defaults and eliminating duplicate entries. After that, the process ensures completeness and corrects any data outliers. This ensures the dataset covers the agreed-upon periods and rectifies any inaccuracies.
The actual cleaning is typically carried out using SQL views, Common Table Expressions (CTEs), User-Defined Functions (UDFs), or lambda functions. Advanced programming models, like dbt or Apache Beam, are employed for more complex pipelines.
Analytics
Analytics involves handling data effectively through querying, processing, and combining. SQL, a common tool, allows for precise data searches, data manipulation, and integration of large datasets. It facilitates complex calculations over groups of data rows for detailed data exploration.
An essential function of analytics is data visualization – turning complex data into understandable charts and reports.
Enabling Team
The Enabling Team function involves supporting domain teams by temporarily joining them to understand their needs and facilitating a smooth transition.
This team plays a pivotal role in fostering a learning environment. They enhance data analytics capabilities and instill Data Mesh principles in domain teams' practices. They also guide these teams in utilizing self-serve data platforms effectively, providing crucial instructions.
They also function as internal consultants rather than product creators. The enabling team produces and distributes a range of educational resources, including examples, best practices, and tutorials.
Now that we know the key functions of Data Mesh architecture, let’s build upon this foundational understanding and see how we can practically implement Data Mesh effectively.
How To Implement Data Mesh
Although Data Mesh is a revolutionary concept in the data world, it is still in the early stages as far as wider adoption is concerned. It poses challenges for data teams when creating a systematic implementation plan.
So first of all, let's answer a fundamental question. Do we really need Data Mesh?
The answer to the question depends upon the following factors:
- Data source count: Evaluate the total number of data sources within your organization.
- Data governance priority: Understand the level of priority your organization places on data governance.
- Data team size: Determine the number of data analysts, engineers, and product managers in your data team.
- Data engineering bottlenecks: Identify the frequency of instances where the data engineers impede the launch of new data products.
- Data domain number: Assess the number of functional teams (e.g., marketing, sales, operations) that rely on your data sources along with the total number of products and data-driven features.
Unlocking The Power of Data Mesh: Guide To Best Practices
Implementing Data Mesh involves both technical and cultural changes. It requires thorough planning, collaboration, and alignment with business goals. Here are some best practices for implementing Data Mesh:
Selecting An Appropriate Pilot Project
When starting with a Data Mesh, always choose a pilot project. This initial small-scale project allows for a controlled environment to evaluate the efficacy of the new data architecture.
Progressive Platform Development
During the implementation of a Data Mesh, waiting for a perfect platform causes unnecessary delays. The focus should be on setting achievable goals and making incremental improvements.
Clear Definition Of Self-Service
Self-service in a Data Mesh means building an architecture that fits your business needs. It's important to spot the features that will give you the most value.
Independent Domains
A critical step in implementing a Data Mesh is defining data domains and equipping them with the necessary expertise to function independently.
Trustworthy Data Products
In the Data Mesh, each team is responsible for the reliability of their data products. As such, teams should document rules for constructing these products and governance structures.
Striking A Balance In Governance
Data governance in a Data Mesh should strike a balance between data accessibility and risk management.
Identifying Critical Domains & Data Products
Another important step towards decentralization is identifying and marking domains and data products vital to the business.
Domain-Driven Design Principles
Understanding domain-driven design principles is vital when implementing a Data Mesh. These principles ensure the alignment of data products with business objectives and user needs.
Formation Of A Data Platform Team
A dedicated data platform team should be formed to support the Data Mesh infrastructure.
Optimal Tech Stacks For Data Mesh Success
Data Mesh, at its core, is an organizational strategy – it's not something that can be purchased off-the-shelf from a vendor. Nonetheless, the role of technology is indispensable as it catalyzes the implementation of a Data Mesh. The key to gaining acceptance from domain teams lies in using user-friendly solutions.
Many platforms currently offer an ample range of self-serve data services, providing a solid foundation for building a Data Mesh. Following is the list of services that can assist in kickstarting your journey toward implementing a Data Mesh.
- Databricks
- MinIO and Trino
- dbt and Snowflake
- AWS S3 and Athena
- Google Cloud BigQuery
- Azure Synapse Analytics
- Starburst Enterprise (TBD)
How Effective Is Estuary As A Solution For Implementing Data Mesh?


Estuary, our dynamic DataOps tool, offers several features that make it an effective solution for implementing Data Mesh:
User-Friendly Interface
Estuary is designed with engineers, data scientists, and business stakeholders in mind. Its user-friendly web interface makes it accessible to a wide range of users and enables them to easily navigate and utilize its capabilities.
Powerful Data Streaming
Estuary leverages the capabilities of data streaming, allowing for the creation of powerful and scalable data pipelines. This enables efficient capture and dispatch of data across various databases, file storage systems, data lakes, SaaS applications, or a data warehouse.
Ready-To-Use Connectors
Flow provides ready-to-use connectors that make it easier to integrate with diverse data sources and destinations. This reduces the complexity and effort required to set up data pipelines and facilitates seamless data transfer across different systems.
Self-Service Platform
Within a Data Mesh structure, Estuary serves as a unified, self-service platform. It empowers stakeholders from different sectors to independently construct and disseminate data products known as collections. This self-service capability fosters a decentralized approach to data ownership and utilization.
Universal Governance Standard
Flow implements a universal governance standard, acting as a go-between for all other data systems within the organization. It helps enforce governance policies, ensure data quality and compliance, and streamline data management processes. This standardization simplifies complex tasks and contributes to the overall efficiency of data management within the Data Mesh context.
Conclusion
Embracing Data Mesh architecture is a strategic pivot that empowers organizations to manage and use their data assets effectively. It’s a transformative approach that breaks down monolithic structures, paving the way for a more distributed, domain-centric model.
While there are no specific tools uniquely designed for Data Mesh, the beauty of this architecture lies in its ability to use different platforms.
One of the tools that meet the needs of Data Mesh is Estuary. Estuary, within Data Mesh, delivers a holistic solution, boosting collaboration and hastening data product creation by dismantling data silos.
If you are looking to implement Data Mesh in your organization, signup for Estuary and explore its many benefits, or contact our team to discuss your specific needs.
Interested in diving deeper into the world of data mesh architecture? Explore these insightful resources:
- Discover essential data mesh tools and their role in revolutionizing data management: Data Mesh Tools.
- Uncover the distinctions between a data lakehouse and a data mesh, and their implications for modern data ecosystems: Data Lakehouse vs. Data Mesh
- Learn about the core principles underpinning the data mesh paradigm and how they shape effective data stratgeties: Data Mesh Core Principles.


