





















In the past few years, open table formats have shaken up most of the data world. They have revolutionized how data lakes are managed which led to the Data Lakehouse. This article aims to explain key aspects of open table formats, their evolution, and their impact on data lake ecosystems.
We will take a look at leading formats like Apache Iceberg, Delta Lake, and Apache Hudi, providing insights into their technical methodologies and implementation strategies and we’ll also discuss how catalogs fit into the lakehouse architecture to demystify some of the confusion and complexity around Snowflakes and Databricks catalog services; Polaris and the open source Unity Catalog.
Background and Evolution
Before we jump into the technical details, let's take a look at how we got to this point.
Unlike traditional operational and analytical databases, the Data Lake and its successor, the Data Lakehouse, is not a database, at least not in the traditional sense of the word. To explain, we have to start with the foundation of the Lakehouse, which is the Data Lake. There are many definitions of a data lake, some include processing engines, some don’t, but what most organizations agree on is that it is about storing data.
A data lake is a centralized repository designed to store large amounts of structured, semistructured, and unstructured data. It can store data in its native format and process any variety of it, ignoring size limits.
The main components of a Data Lake are:
- A distributed file system with low storage costs and strong guarantees of fault tolerance;
- Files in this distributed FS, which can be anything: text, logs, bits, tables, etc;
Which, extended with the following, comprise a Data Lakehouse:
- A query engine or framework that allows us to run SQL queries against these files;
- A catalog, whose purpose is to store metadata, manage access control, and facilitate data discovery.
- A metastore that is responsible for storing and providing metadata for data operations, such as table definitions and transaction management.
As a result of integrating these services, we have quite cheap cold storage that is very good for storing anything, coupled with a data processing system for the analysts working with it.
Traditional data lakes, while flexible and scalable, faced significant challenges such as limited support for CRUD operations, scalability issues, and lack of ACID compliance. These limitations hindered their ability to handle transactional data efficiently and maintain data consistency.
The advent of modern open table formats addresses these challenges, bringing data lakes closer to the functionality of data warehouses, which also happens to explain how the term “Lakehouse” came to be. The original whitepaper from Databricks is a great read on the topic.
In the rest of this article, we’ll see how data lakes become data lakehouses step by step.
Storing data is essential as the volume of generated data continues to increase. Object stores like S3 are cost-effective but lack data consistency guarantees, so they are unsuitable for building transactional tools. Table formats provide a solution to this problem.
Table formats refer to the structure and encoding of data within a table in a database or data storage system. They define how data is stored, organized, and accessed, influencing performance, interoperability, and the capabilities available for data processing. Think of them as a specification, not as a service.
Let’s take a look at them in a bit more detail.
Table Formats
The first popular table format was Hive.

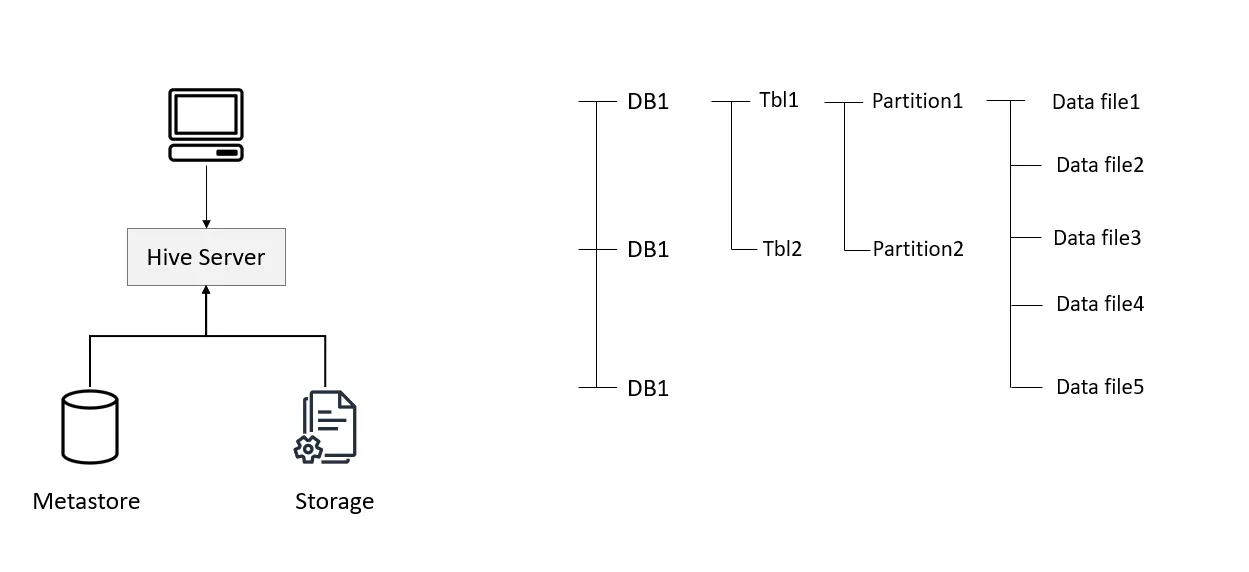
Hive is a data warehousing solution built on top of Hadoop, designed to facilitate data summarization, querying, and analysis. Despite its widespread use, the Hive table format has several significant drawbacks. These include stale table statistics due to partition lifecycle issues, the necessity for users to understand the physical data layout, and a lack of data lineage, history, and schema evolution.
Hive was originally developed in the pre-cloud era and was not optimized for modern object storage solutions like AWS S3, making its data organization structure somewhat incompatible with them. As cloud usage gained popularity and its patterns evolved, Hive users began to experience lots of frustration due to performance degradation and complexity issues.
With time, new use cases have emerged, demanding advanced capabilities from data lakes that the traditional Hive system cannot provide. These new requirements highlight the need for enhanced features to support modern data workflows effectively. Enter modern open table formats.
Modern table formats, including Apache Iceberg, Delta Lake, and Apache Hudi, enhance data lake functionality in multiple ways. One of the most important is supporting full Create, Read, Update, and Delete (CRUD) operations. This capability is crucial for maintaining data consistency and enabling real-time data updates.
- Create: This operation allows new data to be added to the table. For example, in Delta Lake, data can be added using SQL commands that define and populate new tables.
- Read: This operation retrieves data from the table. Efficient querying and data retrieval are supported through optimized metadata handling and data partitioning.
- Update: This operation modifies existing data within the table. Both Delta Lake and Apache Iceberg support updates through their respective transaction mechanisms, ensuring that data integrity is maintained.
- Delete: This operation removes data from the table. The use of transaction logs and snapshots in formats like Iceberg and Delta Lake allows for the safe deletion of records without affecting the overall data integrity.
For instance, Delta Lake provides robust support for CRUD operations through its ACID transaction capabilities, ensuring reliable data manipulation within data lakes. Apache Iceberg also supports these operations by leveraging a snapshot-based approach to track changes, thereby allowing efficient data updates and deletions without compromising performance.


As you can observe, the underlying structure of these table formats is eerily similar, and as time passes, their functionalities become more and more overlapping with each other as well.
Performance and Scalability
The latest table formats improve performance and scalability by organizing data at the file level rather than the folder level. This approach enables more efficient data querying and retrieval, significantly enhancing the speed of data operations.

- File-Level Organization: Data is partitioned and organized within files rather than directories, which enhances query performance. For instance, Apache Iceberg uses hidden partitions to manage large datasets efficiently.
- Efficient Metadata Handling: Formats like Delta Lake maintain a transaction log that records all changes to the data, enabling efficient querying and ensuring data consistency.
- Dynamic Schema Evolution: This feature allows the table schema to evolve over time without requiring a full table rewrite, accommodating changes in data structure seamlessly.
For example, Iceberg and Delta Lake optimize query performance by partitioning data intelligently and maintaining efficient metadata handling. Iceberg's use of hidden partitions and dynamic schema evolution allows for effective data pruning and faster query responses, while Delta Lake’s optimized handling of metadata enhances its scalability and performance.
Transactional Support and ACID Compliance
Transactional support and ACID compliance are fundamental features of modern table formats.
- Atomicity: Ensures that all parts of a transaction are completed successfully. If any part fails, the entire transaction is rolled back.
- Consistency: Guarantees that transactions bring the database from one valid state to another, maintaining data integrity.
- Isolation: Ensures that concurrent transactions do not interfere with each other, preventing data corruption.
- Durability: Ensures that once a transaction is committed, it remains so even in the event of a system failure.
These formats ensure that transactions are processed reliably, which is essential for complex ETL processes and real-time data analytics. Delta Lake provides ACID transactions, scalable metadata handling, and versioning, ensuring data integrity and enabling reliable concurrent data operations. Similarly, Apache Iceberg offers ACID transactions, time travel, and schema evolution, allowing users to handle large datasets effectively while maintaining data integrity and accommodating structural changes over time.
Organizing data stored in an object storage based on a table format’s specification is a good start, but to enable functionality similar to a data warehouse, we need a bit more. Let’s see what the next steps are to implement the Lakehouse.
The Architecture of Data Lakehouses
The architecture of a data lakehouse combines elements of both data lakes and data warehouses to provide a unified and scalable data management solution. This hybrid architecture aims to offer the best of both worlds by supporting the storage and processing capabilities of data lakes with the management, governance, and performance features of data warehouses.
Because of the modular nature of Lakehouses, it makes sense to treat its components as separate services when trying to explain the term. Let’s take a look at the building blocks:
- Storage Layer
- Data Lakes: Utilizes cost-effective, scalable storage for raw, structured, semi-structured, and unstructured data combined with a table format, such as Apache Iceberg or Delta Lake.
- File Format: Supports various data formats like Parquet, ORC, Avro, JSON, etc.
- Table Format: A logical metadata layer to help organize the raw files into tables. Apache Iceberg, Delta Lake, Apache Hudi
- Compute Layer
- Query Engines: Supports SQL and other query languages for data processing (e.g., Apache Spark, Presto, DuckDB).
- Processing Frameworks: Batch and stream processing frameworks for data transformation and analysis.
- Metadata Management
- Catalogs: Organize and manage datasets, providing a high-level structure for databases and tables. Enable data discovery, access control, and governance.
- Metastores: Store detailed metadata about datasets, including schema information, table definitions, and partition details. Integrate with query engines to facilitate data operations.
- Governance and Security
- Access Control: Fine-grained security policies to manage user permissions and data access.
- Data Lineage: Track the origins and transformations of data to ensure transparency and compliance.
These 4 components comprise the foundational layer of a Data Lakehouse, most commonly deployed as separate, integrated services. Because connectivity is top of mind in an architecture like this, it’s not uncommon for data engineers to swap out certain services over time. Sometimes a better compute layer comes along (hello DuckDB!), or sometimes there’s a new catalog that is worth migrating to.
You can also extend this architecture with ETL/ELT tools like Estuary or BI services, such as Tableau or Power BI.
Differences from Data Lakes and Data Warehouses
One of the most common questions data engineers encounter pertains to the distinction between data lakes, data warehouses, and data lakehouses. Let's take a few minutes to dive into this topic in detail.


- Data Lakes: Primarily focus on storing large volumes of raw data in its native format. They lack robust management, governance, and performance optimization features.
- Strengths: Cost-effective storage, and flexibility in data formats.
- Weaknesses: Limited support for ACID transactions, governance, and performance optimizations.
- Example: Flat files stored in an S3 bucket.
- Data Warehouses: Designed for structured data and optimized for complex queries and transactions. They provide strong governance, security, and performance but can be expensive and less flexible.
- Strengths: High performance, strong ACID compliance, governance, and security.
- Weaknesses: Higher costs, and limited support for unstructured data.
- Example: Snowflake, Redshift.
- Data Lakehouses: Merge the strengths of data lakes and warehouses by providing scalable storage and robust data management and governance.
- Strengths: Unified architecture, support for both structured and unstructured data, cost-effective storage, strong governance, and performance optimizations.
- Example: A combination of S3 as a storage layer, Unity Catalog for metadata handling & governance, and DuckDB as a query engine.
As you can see, while there is overlap in functionality, the goal of each architecture is different enough to warrant understanding them.
To bridge the gap between a Data Lake and a Warehouse, one of the most important components is the catalog. Let’s take a look at what it is responsible for.
Asset Management in Data Lakehouses with Catalogs
Catalogs provide a higher-level organizational structure for datasets and other resources, grouping them into logical units like databases and tables.
The term "catalog" in the data world is used in various contexts and often leads to confusion due to its broad application. Here’s a breakdown of some of the different types of catalogs and their specific roles:
Catalogs for Data, Metadata and AI:
- Role: Manages metadata for large AI assets, analytic tables (including open table formats, such as Iceberg), including schema, partitioning, and versioning.
- Example: Polaris, Unity Catalog, Apache Atlas
File Catalogs:
- Role: Organizes and retrieves files based on metadata attributes like size and creation date.
- Example: AWS Glue Data Catalog manages metadata for files stored in Amazon S3.
Data Catalogs:
- Role: Provides a unified view of data assets for discovery, governance, and analytics.
- Example: Alation.
“What exactly does a data lake catalog do?” You may ask. Here’s the answer:
- Metadata Management: Store metadata about datasets, including schema, table names, column types, and descriptive information.
- Access Control: Implement security policies to control data access at various levels, ensuring compliance and data protection.
- Data Discovery: Facilitate the discovery of datasets by enabling users to search based on metadata attributes.
- Governance: Support data governance initiatives by maintaining accurate and up-to-date metadata, tracking data lineage, and ensuring data quality.
Let’s illustrate how a user might actually interact with a catalog with a simple scenario.
A data analyst, Jane, needs to analyze sales data stored in a lakehouse architecture. She wants to execute a SQL query to aggregate sales data by region for the last quarter. This scenario outlines the lifecycle of her interaction with the data catalog from query execution to result retrieval.
Step-by-Step Lifecycle
Query Submission: Jane uses her preferred SQL client (e.g., a Jupyter notebook or a SQL IDE) to write and submit the following query:
plaintextSELECT region, SUM(sales_amount) as total_sales
FROM sales_data
WHERE sales_date BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY region- Catalog Interaction:
- The SQL client sends the query to the compute engine (e.g., Trino or DuckDB).
- The compute engine parses the query and recognizes the sales_data table.
- The compute engine then interacts with the metadata catalog to fetch the schema and partition information for sales_data.
- Metadata Retrieval:
- The catalog receives the request and retrieves metadata for the sales_data table. This includes information about the schema, data locations, file formats, and any partitioning details.
- The catalog may also check for access permissions to ensure Jane is authorized to access the sales_data table.
- Data Location Resolution:
- The catalog returns the metadata to the compute engine.
- Using this metadata, the compute engine determines the physical locations of the data files that need to be read to fulfill the query.
- Query Optimization:
- The compute engine uses the metadata to optimize the query plan. This involves selecting the most efficient way to read the necessary data, applying any relevant filters, and determining the best strategy for aggregation.
- The compute engine might push down some operations (e.g., filters) to the storage layer if supported, reducing the amount of data that needs to be processed.
- Data Reading:
- The compute engine reads the relevant data files from the storage layer (e.g., a distributed file system or object storage) based on the locations and partitions specified by the catalog.
- The data is processed in-memory according to the optimized query plan.
- Execution and Aggregation:
- The compute engine executes the query, aggregating the sales data by region as specified.
- Intermediate results are held in-memory or spilled to disk if necessary, depending on the compute engine's capabilities and the size of the data.
- Result Delivery:
- Once the computation is complete, the final results are sent back to Jane’s SQL client.
- Jane sees the aggregated sales data by region for the last quarter displayed in her SQL client.
- Query Logging and Metadata Updates:
- The catalog logs the query execution details for auditing and performance-tracking purposes.
- If the catalog supports it, metadata such as query statistics or usage patterns might be updated to improve future query optimizations.
- User Feedback:
- Jane analyzes the results and may provide feedback or further refine her query based on the insights gained.
- She may also decide to save the query or share it with colleagues for collaborative analysis.
Although there have been a few open catalogs in recent history, such as Apache Ranger; two emerging catalogs in this space are Snowflake’s Polaris Catalog and Databricks’ OSS Unity Catalog, both of which aim to address the complexities of multi-engine data environments while promoting open standards and vendor neutrality.
Compute Engines and Data Catalogs don’t always play nice with each other. Open standards like the REST catalog for Iceberg help bridge this gap of interoperability. This is something Polaris tackles by embracing open standards.
Iceberg Catalogs
To set the stage around catalogs, let’s take a look at their history a bit. There are two primary categories of Iceberg catalogs: service catalogs and file system catalogs. Understanding the differences between these types and how they interact with the broader data ecosystem is key to efficiently managing data operations.
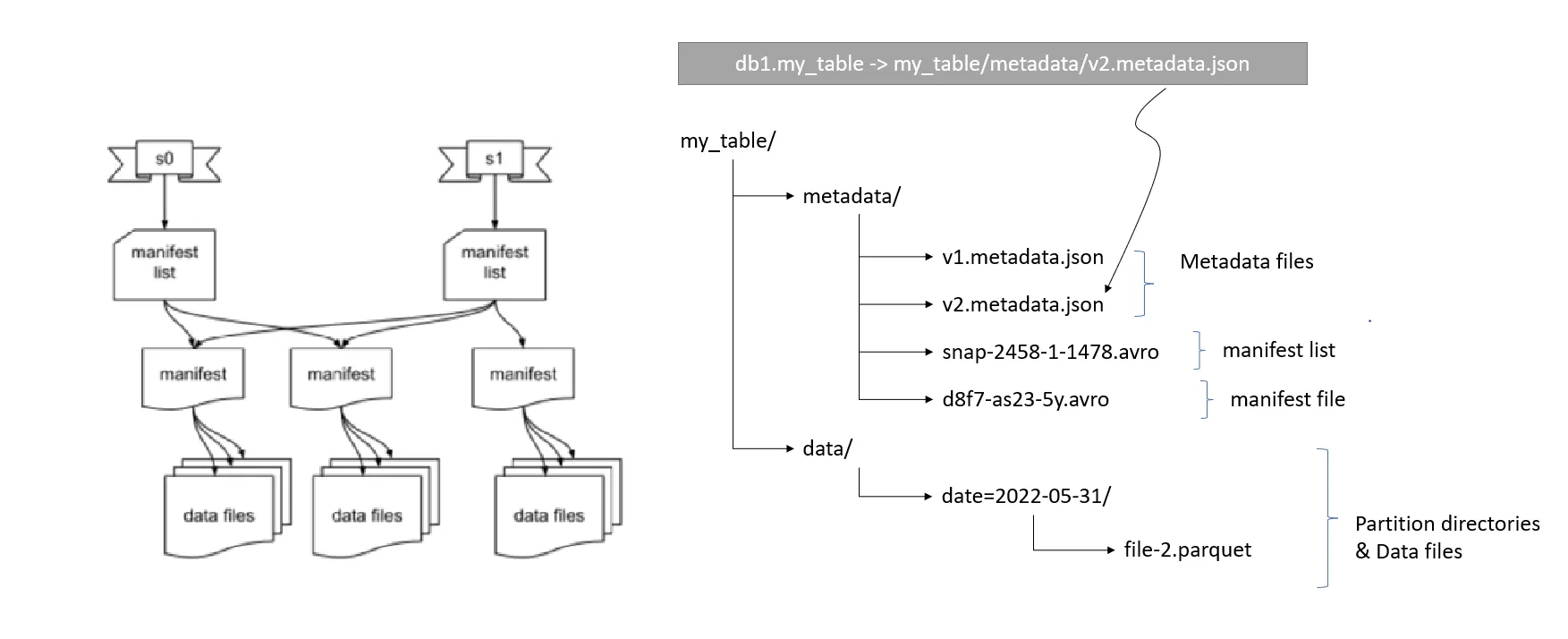
Service catalogs, such as JDBC, Nessie, and AWS Glue, represent running services that store references to metadata in a backing relational database. When a table operation, such as a write or update, occurs, the service catalog updates the metadata reference to point to the latest metadata file. For instance, if table A is updated, a new metadata JSON file (e.g., V2 metadata.json) is created, and the catalog updates its reference to this new file.
This mechanism ensures consistency in data views across different engines like Trino and Spark, which rely on the catalog to know which metadata file to reference.


On the other hand, file system catalogs, sometimes referred to as “Hadoop catalogs”, operate differently. They rely on a version-hint.text file stored within the storage system to indicate the latest metadata file. When using a file system catalog, engines will scan the storage to find this version hint text, which directs them to the appropriate metadata file. This method can lead to issues if not managed properly, especially when trying to switch between different types of catalogs or when dealing with concurrent writes, as certain object stores may not guarantee atomic updates to the version hint text.
It is advisable to use service catalogs due to their robust locking mechanisms that prevent conflicts during concurrent writes.
Future developments aim to simplify this landscape by standardizing on a REST catalog specification. This approach would provide a unified interface for different catalogs, reducing the complexity of managing multiple catalog types and enhancing interoperability within the lakehouse stack.
REST Catalog
This REST catalog specification ensures that regardless of the underlying catalog service used, the same logic and connectors can be applied, streamlining the process of discovering and querying Iceberg tables.
It centralizes the catalog functions, ensuring consistent behavior and metadata format for clients written in various languages like Python, Java, C++, and Rust. This approach facilitates cross-platform interaction, supports multiple versions of clients, reduces conflicts during metadata updates, and enables new features that are difficult to implement with legacy catalogs.
The goal of the REST catalog is to ultimately enhance compatibility and integration within the data warehouse ecosystem.
Key Advantages:
- Cross-Platform Consistency: Ensures uniform behavior and metadata format across different clients and languages.
- Support for Multiple Versions: Facilitates the coexistence of older and newer clients, easing the migration process in large infrastructures.
- Enhanced Commit Process: Utilizes a diff-based commit process to reduce conflicts during metadata updates, allowing server-side conflict resolution and retries.
- Future-Proofing: Supports new features like multi-table transactions, which are challenging to implement with legacy catalogs.
- Broader Compatibility: Enables any system that can communicate with the REST catalog to interact with the data warehouse, promoting the integration of new technologies.
Let’s take a look at two catalogs that focus on the REST interface.
Polaris Catalog: Open Source Catalog for Apache Iceberg


Polaris, introduced by Snowflake, is designed to enhance interoperability and reduce the complexity of managing data across multiple engines and platforms. Built to support Apache Iceberg’s open standards, Polaris aims to eliminate vendor lock-in and enable seamless data operations across various infrastructures.
Key Features:
- Open Source and Enterprise-Ready: Polaris is open-sourced to encourage community contributions and is designed to provide enterprise-level security and functionality.
- Interoperability: It supports read and write operations across multiple engines such as Apache Flink, Apache Spark, and Trino, using Iceberg's open REST API.
- Hosting Flexibility: Users can host Polaris on Snowflake’s AI Data Cloud or their own infrastructure using containers like Docker or Kubernetes.
- Atomic Transactions: Ensures reliable table operations with support for atomic transactions, allowing concurrent modifications and accurate query results.
- Governance Integration: Polaris integrates with Snowflake Horizon, extending governance features like column masking, row access policies, and object tagging to Iceberg tables.
Advantages:
- Vendor-Neutral Storage: By adhering to open standards, Polaris allows enterprises to avoid vendor lock-in and maintain flexibility in their data architecture.
- Cost Efficiency: Reduces the need for multiple data copies and minimizes storage and compute costs by enabling multiple engines to operate on a single data copy.
- Community and Ecosystem Support: Backed by the Apache Iceberg community, Polaris benefits from a wide range of integrations and community-driven enhancements.
OSS Unity Catalog: Universal Catalog for Data and AI Governance


Databricks’ Unity Catalog is an open-source initiative to create a universal catalog that manages data and AI assets across various clouds, data formats, and platforms. Unity Catalog aims to provide unified governance, improve data interoperability, and support a wide range of data formats and processing engines.
It is a complete rewrite of the proprietary Unity Catalog that has been powering Databricks environments for a few years now. UC offers a 3-level namespace design, which requires careful consideration during this system design phase, so keep it in mind!


Key Features:
- Open Source API and Implementation: Built on OpenAPI spec and Apache 2.0 license, Unity Catalog supports APIs compatible with Apache Hive's metastore and Apache Iceberg's REST catalog.
- Multi-Format and Multi-Engine Support: Extends support to Delta Lake, Apache Iceberg, Apache Parquet, CSV, and more, enabling a wide range of engines to read cataloged data.
- Multimodal Asset Management: Manages tables, files, functions, and AI models under a single governance framework.
- Unified Governance: Provides centralized audit logs, unified lineage tracking, and consistent governance policies across all data and AI assets.
- Community and Ecosystem Support: Supported by major cloud providers and data platforms, including AWS, Microsoft Azure, Google Cloud, and more.
Advantages:
- Open Foundation: By open-sourcing Unity Catalog, Databricks ensures that organizations have a robust, vendor-neutral foundation for current and future data and AI workloads.
- Integrated Governance: Facilitates integrated governance of structured and unstructured data, AI models, and other data assets, simplifying compliance and security.
- Interoperability: The open APIs enable seamless integration with a wide range of data tools and platforms, promoting a collaborative data ecosystem.
- Extended AI asset management: A unique feature compared to other catalogs is that Unity can accommodate AI models and even vector databases into its governance framework.
Unity Catalog is available on GitHub, with continuous enhancements planned to expand its capabilities. Databricks aims to include additional APIs for table writes, views, Delta Sharing, and more, fostering a vibrant open-source community and advancing the state of data and AI governance.
The Final Ingredient: Power!
Central to this architecture are compute engines like Trino and DuckDB, which provide powerful and flexible querying capabilities.


Trino, formerly known as PrestoSQL, is an open-source distributed SQL query engine renowned for its ability to execute fast and interactive queries on large datasets. It supports a wide range of storage formats, including Parquet, ORC, and Delta Lake, enabling users to query data directly in its native format without the need for time-consuming data movement. Trino’s distributed nature allows it to handle complex queries across multiple data sources, making it an ideal fit for the scalable and versatile lakehouse architecture.
Starburst bundles Iceberg with Trino under the name “Icehouse”. Which is, explained in their words:
“An Icehouse is a specialized data lakehouse architecture that leverages Trino as the query engine and Apache Iceberg as the table format.”
DuckDB, on the other hand, is an embeddable SQL OLAP database engine designed for high-performance analytical queries on smaller datasets. Unlike Trino, DuckDB typically operates within a single-node environment, excelling at in-memory processing. It can directly query data stored in file formats like Parquet and CSV, making it a lightweight yet powerful tool for on-the-fly data analysis.
MotherDuck is a great example of building on top of these rock solid data lakehouse components to create a well-oiled data platform; backed by object storages such as S3 and powered by DuckDB for the number crunching.
Both tools support interacting with the table formats and catalogs of the Lakehouse architecture, which makes either of them a perfect fit for this type of modular data stack.
For example, with DuckDB, it’s just a few lines of SQL to get started with querying data residing in a Delta Lake:
plaintextINSTALL uc_catalog;
INSTALL delta;
LOAD delta;
LOAD uc_catalog;
CREATE SECRET (
TYPE UC,
TOKEN '${UC_TOKEN}',
ENDPOINT '${UC_ENDPOINT}',
AWS_REGION '${UC_AWS_REGION}'
)
ATTACH 'test_catalog' AS test_catalog (TYPE UC_CATALOG)
SHOW ALL TABLES;
SELECT * FROM test_catalog.test_schema.test_table;Wrapping up
Open table formats have significantly enhanced the functionality and performance of data lakes, making them a viable alternative to traditional databases for many applications. By supporting full CRUD operations, improving scalability, and ensuring ACID compliance, these formats are transforming the landscape of data management. As the field continues to evolve, the adoption of standardization efforts like REST catalogs will further streamline data operations and unlock new possibilities.
References



About the author
Dani is a data professional with a rich background in data engineering and real-time data platforms. At Estuary, Daniel focuses on promoting cutting-edge streaming solutions, helping to bridge the gap between technical innovation and developer adoption. With deep expertise in cloud-native and streaming technologies, Dani has successfully supported startups and enterprises in building robust data solutions.











