





















Due to the simplicity and versatility of CSV files, it continues to be a preferred choice for data storage and sharing across various domains. As a result, data-driven companies deal with a lot of CSV files to move data from one platform to another. However, if you want to perform analysis, you must centralize the data in a data warehouse like BigQuery. By loading your CSV data into BigQuery, you can run queries and gain valuable insights into your data.
Quick Answer: How to Load CSV to BigQuery
You can import CSV files into Google BigQuery in several ways, depending on your use case and technical preference:
- Command Line (bq load) – Run the bq load command to upload CSV files from Cloud Storage or your local machine.
- BigQuery Web UI – Use the browser interface to manually upload CSV files and define schema settings.
- Web API (Python, etc.) – Programmatically load CSV files into BigQuery tables using client libraries.
- Estuary (Real-Time Option) – Automate CSV-to-BigQuery pipelines with a no-code approach for continuous, real-time integration.
Each method works for different scenarios: CLI and UI are good for one-off uploads, APIs enable automation, while Estuary scales to ongoing real-time data ingestion.
What is Google BigQuery?

Google BigQuery is a fully-managed, cloud-based data warehouse and analytics platform offered by Google Cloud Platform (GCP). It provides a powerful, scalable solution to process and analyze massive amounts of data efficiently. For analysis, you can either use SQL commands or connect business intelligence tools to obtain insights. And for machine learning, you can also leverage the BigQuery ML capability. It allows you to create and deploy ML models using GoogleSQL queries. BigQuery ML supports internally trained models like Linear regression, K-means clustering, and Principal Component Analysis. However, externally trained models like Deep Neural Networks and Random Forest are also supported by BigQuery ML.
BigQuery also has the ability to integrate with a range of other GCP services like Google Cloud Storage, Cloud Dataflow, and Google Cloud Pub/Sub. This allows you to easily transfer data into BigQuery and analyze it using other GCP tools.
Why Import CSV to BigQuery?
CSV, or Comma-Separated Values, is the most common file format for exporting or importing data. While CSV files are widely used, there are some limitations pertaining to processing and analyzing large datasets.
However, Google BigQuery can handle large amounts of data efficiently. When you upload CSV to BigQuery, you can achieve fast query execution. This reduces the time required to obtain insights into your data. BigQuery offers advanced analytics features like ML and geographic data analysis. You can use these features to gain deeper insights for making informed decisions.
Additionally, BigQuery is a pay-as-you-go model, so you pay only for the storage and queries you use. You don’t need any expensive software or hardware for the same.


4 Methods to Import CSV into BigQuery
Whether you’re loading CSV data from cloud storage or a local file, you can load the data into a new BigQuery table or BigQuery partitioned table. You can also append to or overwrite an existing table or partition.
Before you get started with loading your CSV data to BigQuery, ensure that you have a BigQuery dataset to store your data. Then, you can pick one of the different methods to upload CSV to BigQuery:
Method 1: Load CSV to BigQuery Using the Command Line (bq load)
You can use the bq command line tool’s bq load command to load data from a readable data source. A load job is automatically created when you load data using the command line tool. The bq load command will create or update a table and load the data in a single step.
Let’s say you have a dataset named my_dataset with a table named my_table. Then, you can use the following command:
plaintextbq load \
- - source_format=CSV \
my_dataset.my_table \
gs://my_bucket/mydata.csv \
./myschema.jsonThis command loads data from the source file in gs://mybucket/mydata.csv into the table named my_table within my_dataset. For specific schema definitions, the local schema file named myschema.json is included. There are other optional flags you can include in this command to specify additional information. For example, autodetect will enable auto-detection of schema, and ignore_unknown_values will ignore extra, unrecognized CSV values.
If you want to check whether your BigQuery table has been populated, run the following command:
plaintextbq show my_dataset.my_tableIf my_table within my_dataset has all your data, this command will provide detailed information about my_table, including its schema, field names, data types, and other attributes.
While the manual process seems pretty straightforward, it comes with scalability limitations and susceptibility to errors.
Method 2: Upload CSV to BigQuery Using the Web UI
You can use the BigQuery web UI to load CSV data into a BigQuery table. First, you must open the BigQuery web UI. In the Explorer pane, expand your project, and select a dataset you want to load. In the Data set info section, click on Create Table.


In the Create table panel, you must specify details in the required fields. Under the Source section, you’ll have the option to Create a table from Google Cloud Storage, Upload, or Drive, among other options. Select the appropriate option. The File format must be set to CSV.
Similarly, specify the Project, Data set, and Table details in the Destination section. Finally, within the Schema section, you can enable Auto-detect or manually enter the schema information.

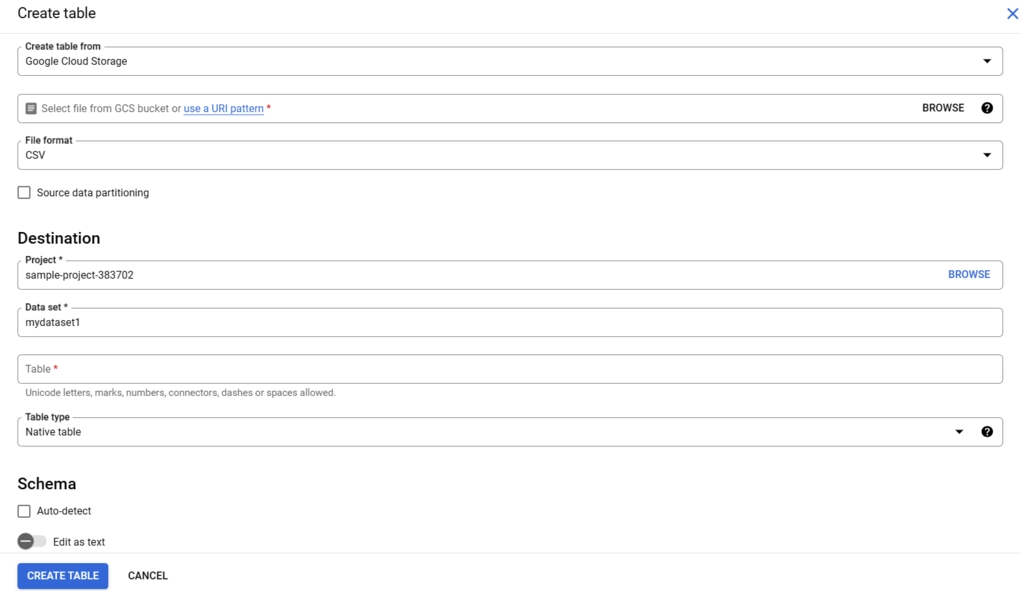
You can scroll down in the Create table panel and check Advanced options for some other parameters like Encryption and Default Rounding Mode. After providing the necessary details, click on the Create Table button. Your CSV data will be fetched, and after ascertaining the schema, the table will be created and populated with the CSV data.
Method 3: Import CSV into BigQuery with the Web API (Python Example)
If you’re an avid programmer and want to upload CSV to BigQuery programmatically, you can use BigQuery APIs. Using the BigQuery APIs is a flexible way to load data from CSV to BigQuery.
Here’s a sample Python code you can use to load CSV to BigQuery:
plaintextfrom google.cloud import bigquery
client = bigquery.Client()
table_ref = client.dataset('dataset').table('table')
job_config = bigquery.LoadJobConfig()
job_config.source_format = bigquery.SourceFormat.CSV
job_config.skip_leading_rows = 1
job_config.schema = [
bigquery.SchemaField('col1', 'STRING'),
bigquery.SchemaField('col2', 'INTEGER'),
]
with open('/path/to/file.csv', 'rb') as source_file:
job = client.load_table_from_file(source_file, table_ref, job_config=job_config)
job.result() # Wait for the job to complete
table = client.get_table(table_ref)This code uses the load_table_from_file method to add CSV to BigQuery. It specifies the schema of the table with SchemaField objects.
You can also use options like skip_leading_rows and field_delimiter in the LoadJobConfig object for a customized load process.
Method 4: Load CSV to BigQuery in Real Time with Estuary
Wouldn’t you love to have a hassle-free process to upload data to BigQuery, with a low-code approach? While there is a range of multi-purpose data transfer ETL, you can use Estuary for quick and seamless data integration in real time.
Estuary is a promising tool that will help extract your data from CSV and load it in BigQuery. Completing this task will only take a few clicks. However, to get started, you must have a Google Cloud Storage bucket in the same region as the BigQuery destination dataset.
Here’s how you can go about loading data from CSV to BigQuery using Estuary:
Step 1: Log in to Estuary. Don’t have an account yet? You can register for a free account.
Step 2: After logging in, you’ll be redirected to the Estuary dashboard. Click on Captures on the left side of the dashboard to start setting up your source end of the pipeline.


Click on the New Capture button to land on the Create Capture page. You can load CSV data either from Google Sheets or CSV hosted at an HTTP endpoint. Search for Google Sheets or HTTP File in Search Connectors accordingly.


If you have your CSV data hosted at an HTTP endpoint, select the HTTP File connector. On the connector page, provide a Name for the connector and the HTTP file URL. Click on the Next button after you’ve filled in the details, then click on Save and Publish.


If you’ve stored your CSV data in Google Sheets, search for the Google Sheets connector in the Search Connectors box.


Click on the Capture button to navigate to the Google Sheets connector page.


Provide an appropriate Name for the capture and the link to your Spreadsheet. You can mention the number of rows to be fetched when making a Google Sheet API call. Once you’ve filled in the details, then click on Next. Following this, you must click on Save and Publish. This will capture your data from Google Sheets into a Estuary collection.
Step 3: Now that you’ve set up your pipeline’s source end, you can proceed with the destination setup. Navigate to the Estuary dashboard and click on Materializations on the left side.
You’ll land on the Materializations page. Click on the New Materialization button to start setting up the destination end of the pipeline. Since you’re moving data from CSV to BigQuery, search for BigQuery in Search Connectors.


Click on the Materialize button of the BigQuery connector. You’ll be redirected to the BigQuery materialization connector page.
Before connecting BigQuery using Estuary, you must meet a few prerequisites. Ensure you complete these steps before you proceed. Once you’ve completed the steps, you can continue setting up your destination.


Fill in the required fields, like a Name for the connector, Project ID, and Name of the target BigQuery dataset. Once you’ve provided all the details, click on the Next button. If you see that your CSV data wasn’t automatically loaded, use the Collection Selector to add the captured CSV data. Then, click on Save and Publish.
If you’re working across multiple destinations, check out our guides on CSV to Snowflake and CSV to PostgreSQL for similar real-time setups.

If you’d like more information and detailed instructions, here’s the Estuary documentation on:
- The Google Sheets source connector
- The HTTP File Capture Connector
- The BigQuery materialization connector
- How to create a Data Flow like this one
Conclusion: CSV to BigQuery
You have several options to load CSV files into BigQuery:
- Use the command line (bq load) for simple uploads.
- Use the BigQuery Web UI for one-off, manual imports.
- Use the Web API for programmatic and automated workflows.
- Use Estuary to build a real-time, no-code pipeline that continuously syncs CSV data into BigQuery.
While the first three methods work well for smaller, occasional jobs, they can become error-prone and hard to scale. Estuary offers a seamless alternative, giving you reliable, continuous ingestion from CSV to BigQuery with minimal setup.
Get started with Estuary today. Your first pipeline is free!


